
Ctrl+AI+Reg — Top 10 enforcement patterns in AI regulation
How AI regulation is actually enforced, worldwide — a living essay grounded in the data of the Global AI Regulation Tracker.

Welcome to the new era of Ctrl+AI+Reg
From now on, you will receive:
- weekly wrap of AI regulatory updates (+ ‘big picture analysis’ for paid subscribers)
- monthly essay issue (e.g. this newsletter)
In my latest special update, I shared that Ctrl+AI+Reg is shifting away from being a news digest. You can now access the weekly digest for free in the ‘GLOBAL UPDATES’ tab of the Global AI Regulation Tracker.
This newsletter is pivoting towards higher level intelligence and analysis — connecting the dots between regulatory moves rather than simply listing them. The below essay is the first expression of that direction.
Introduction
The 10 patterns are:
1) Privacy regulators are the most active AI enforcers — and they do it with law written before AI
2) Automated-decision rules are growing out of privacy and data-protection law, not dedicated AI statutes
3) The world has converged on synthetic-media rules but not on enforcing them
4) Competition authorities span a spectrum of activity on AI, from light monitoring to active enforcement
5) Compute control is enforced at the border, one shipment at a time — even as the formal rules loosen
6) Bans move faster than fines
7) Copyright’s hardest questions are being dealt in court, not by statute
8) Binding rules on frontier models are arriving faster than the enforcement behind them, and technical standards are setting the working definition of compliance
9) Liability is the next enforcement front, and it is shifting onto model developers
10) Agentic AI’s first real failure will force the jump from voluntary standards to enforcement
Almost every jurisdiction now regulates AI in some way. The harder question is how — and whether the resulting rules connect into patterns across regions and topics or simply accumulate. Drawing on the data in this tracker, this essay sets out those patterns, and concentrates on the stage where most analysis stops short: not how AI regulation is theorised or drafted, but how it is actually enforced. As a ‘live and breathing essay’, this essay rewrite itself whenever a new entry is added, so the patterns described here move with the data. It is written for readers at every level, from those new to the field to the practitioners, policymakers and regulators who work in it daily. It is intended both as a reference for the big picture of AI regulation and as a framework for making sense of individual updates as they appear — and for anticipating the next regulatory move.
1) Privacy regulators are the most active AI enforcers — and they do it with law written before AI
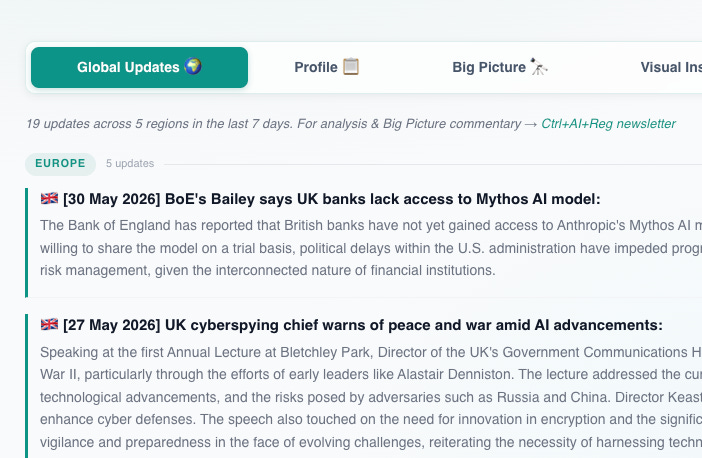
Privacy, data protection and cybersecurity account for the largest share of regulatory activities in the tracker by a wide margin: together 1,825 entries across 133 jurisdictions, against roughly 240 entries under copyright and fewer than 180 under competition law. This margin reflects the data-intensive nature of AI: building and operating a model means processing large volumes of personal data across both B2B and B2C services, which brings a single deployment within reach of privacy, data-protection and cybersecurity law at the same time. These three areas nonetheless operate independently of one another. A system can be fully secured and still process personal data unlawfully, and it can satisfy data-protection requirements and still be insecure; because compliance with one says nothing about the others, a single deployment may have to answer to all three at once. The most prominent interventions to date have come through data protection specifically, each applying law that pre-dated AI: Italy’s data protection authority restricted ChatGPT in 2023 and fined OpenAI EUR 15 million in December 2024 (later annulled on appeal in March 2026 on jurisdictional grounds, without a decision on the substance); Brazil’s authority suspended Meta’s use of personal data for model training in July 2024; and the Netherlands fined Clearview AI in September 2024 for building a facial-recognition database without consent. The privacy-anchored approach is not confined to enforcement; it is also shaping how newer entrants build their national strategies. Nigeria published a National AI Strategy in August 2024 built on a data-protection and cybersecurity foundation, and Kenya released its National AI Strategy 2025–2030 in March 2025 with data governance as a central element. Both adopt the data-protection template as the entry point rather than a dedicated AI statute, which indicates that the pattern described here is becoming the default approach for newer entrants, not a characteristic of established regulators alone.
Within the three areas, cybersecurity has produced some of the newest and fastest-moving reactions, in step with the spread of agentic systems that create additional points of attack. The disclosure of Anthropic’s Mythos model in April 2026 — reported to identify and exploit software vulnerabilities with unusual effectiveness — drew responses from financial and cybersecurity authorities in several jurisdictions within weeks. The European Commission relied on the cybersecurity obligations that providers of general-purpose models already carry under existing law and supported a staged release; the Bank of England, the Financial Conduct Authority and HM Treasury issued a joint statement; Japan convened a financial-sector task force; and South Korea established a dedicated security committee. China had separately incorporated AI governance duties into its amended Cybersecurity Law, approved in October 2025 and effective January 2026.
2) Automated-decision rules are growing out of privacy and data-protection law, not dedicated AI statutes
Automated decisions — who is hired, granted credit, admitted to a programme or approved for a public benefit — are the applications that most directly determine a person’s access to money, employment and services. Australia’s Robodebt programme, which used automated processes to raise unlawful debts against benefit recipients, remains the clearest documented account of what is at stake when such systems operate without adequate accuracy and human oversight. Yet the binding rules that actually govern these decisions are arriving through privacy and data-protection law, not through the dedicated AI statutes written for the purpose. The lineage is the data-protection right — descended from the General Data Protection Regulation’s provision against being subject to a solely automated decision with legal or similarly significant effects — and it is that instrument, already attached to the personal data these systems process, that is doing the regulatory work.
The pattern is consistent across very different jurisdictions. Australia’s Privacy and Other Legislation Amendment Act, passed in November 2024, adds automated-decision transparency provisions to the privacy regime, with the privacy regulator — the Office of the Australian Information Commissioner — developing the supporting guidance through its regulatory-priorities work, rather than any AI-specific agency. China’s Network Data Security Management Regulation, in force since January 2025, attaches concrete obligations to automated processing, alongside a Cyberspace Administration enforcement action on algorithmic transparency and fairness. Canada’s binding Directive on Automated Decision-Making has governed federal automated decisions since 2023 through administrative-law and privacy machinery. And Brazil’s data-protection authority opened a consultation on the review of automated decisions in November 2024, working through its existing mandate.
By contrast, the dedicated AI statutes built specifically to govern these decisions are the slower and more contested overlay. The European Union’s AI Act assigns such uses to a high-risk category, but those obligations have not taken full effect and the Commission’s Digital Omnibus proposal would postpone them toward 2027. In the United States, Colorado’s Artificial Intelligence Act has had its effective date pushed to June 2026 and its requirements challenged in litigation the federal government joined in April 2026, while the dedicated federal AI Civil Rights Act has been reintroduced across sessions without being enacted. These purpose-built regimes remain works in progress even as the privacy route delivers binding obligations now.
The reason privacy law is winning as the vehicle is practical. It already attaches to the personal data that automated decisions process; it comes with standing regulators and enforcement machinery; and it sidesteps the political fight over creating a new AI-specific regime from scratch. The implication for anyone trying to anticipate automated-decision obligations is to watch the data-protection regulators and privacy statutes at least as closely as the headline AI bills — the binding rules are arriving there first, and a dedicated AI statute is increasingly a second layer on top of a privacy-law foundation rather than the foundation itself.
3) The world has converged on synthetic-media rules but not on enforcing them
Major jurisdictions diverge on most aspects of AI regulation, but they have converged on synthetic media and child safety, because the harms are specific and serious enough to command agreement. Coordination is partly formal: the Global Online Safety Regulators Network brings together the internet regulators of Australia, the United Kingdom, France, South Korea, South Africa, Fiji, Ireland and Slovakia. Activity has concentrated on two areas — AI-generated child sexual abuse material, addressed by measures such as the United States TAKE IT DOWN Act and Cyprus’s 2025 criminal offence, and electoral integrity, addressed by rules on AI-generated political content in Singapore, Brazil, South Korea and the United Arab Emirates.
The frameworks tend to rest on three components: (1) obligations on platforms to remove material, (2) requirements to detect and label synthetic content, and (3) criminal liability for those who create harmful material. Because these components recur across jurisdictions, an organisation that builds to the most demanding version of each is likely to meet requirements in most markets. China’s Measures for the Identification of Synthetic Content Generated by AI, issued in March 2025 and mandatory from September 2025, set one of the more demanding labelling standards. India adopted amendments to its Information Technology intermediary rules in February 2026 that specifically address “synthetically generated information”, requiring labelling and traceability and applying the obligations through an existing intermediary-liability framework rather than a dedicated AI statute. This follows the same three-component model used elsewhere, which supports the view that the standards are settling into a common international form even as the leading jurisdictions move on to other topics.
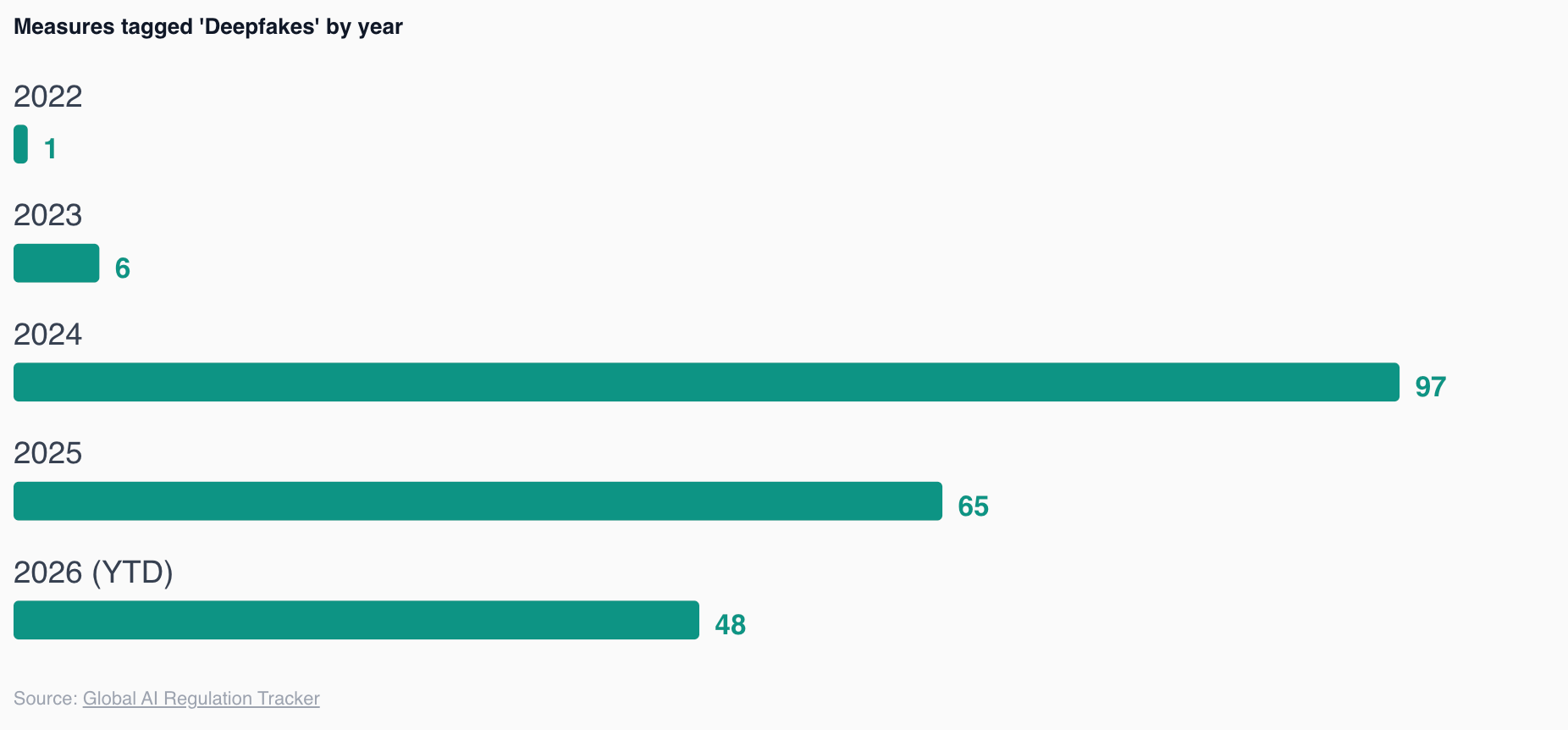
The tracker data indicates that the burst of legislative activity specific to deepfakes has begun to level off rather than continue to accelerate. Measures tagged to deepfakes rose to a high point in 2024 and eased the following year, even as the overall volume of AI rules continued to increase. The 2026 figure is year-to-date and therefore provisional, so it should be read with caution; on the data available it is consistent with a plateau rather than a renewed surge. This pattern suggests that the convergence has largely taken place and that new regulatory attention is moving to other subjects, most visibly agentic systems, where the number of new measures is still rising.
That convergence met its first global test in January 2026, when X’s Grok assistant was used to generate non-consensual sexual deepfakes, including of minors. The reaction drew on the same three components and arrived almost simultaneously across more than a dozen jurisdictions: the United Kingdom brought its deepfake-image offence into force immediately and designated it a priority offence under the Online Safety Act, California’s Attorney General opened an investigation into xAI, and the European Commission ordered X to preserve all Grok-related documents while weighing a ban on “nudification” apps under the AI Act. The speed and uniformity of that response confirm that the substantive standard — that non-consensual synthetic intimate imagery is prohibited — has genuinely converged. Brazil had already moved against the same provider, where the data protection authority, the Federal Public Prosecutor’s Office and the National Consumer Secretariat issued joint recommendations to X over non-consensual sexual deepfakes and concluded in February 2026 that the company’s corrective measures were insufficient, and Turkey had gone further in July 2025, when a court ordered the blocking of specific Grok outputs.
Yet the same episode exposed how unevenly a converged standard can be enforced. Existing law often did not reach a chatbot cleanly: the United Kingdom’s Ofcom determined that xAI fell outside its jurisdiction because Grok is not a user-to-user service, and the Commission reached for the AI Act’s systemic-risk provisions precisely because the conduct sat awkwardly under existing rules. Many regulators therefore fell back on the pre-AI privacy machinery described above, opening data-protection inquiries into X in Ireland, the United Kingdom and Canada. Convergence on what the rule forbids, in short, has outpaced convergence on which regulator can compel a resistant provider to comply.
4) Competition authorities span a spectrum of activity on AI, from light monitoring to active enforcement
Competition authorities placed AI high on their agendas out of concern that a small number of established technology firms could control the critical inputs to AI — computing power, data, cloud capacity and specialised expertise. The principal focus has been high-profile partnerships between cloud providers and model developers (such as Microsoft with OpenAI, and Amazon and Google with Anthropic), examined to determine whether they function as mergers that exclude competitors. Authorities have relied largely on existing competition tools, particularly merger control and rules on abuse of dominance, which together account for 176 measures across 32 jurisdictions in the tracker. What varies between them is not the theory of harm, which is broadly shared, but the intensity of activity — and that intensity runs along a spectrum that cuts across regions rather than dividing them.
At the lightest end sit authorities that are monitoring and issuing guidance without opening cases. Singapore’s competition regulator published an AI self-assessment toolkit for businesses, and Australia’s competition regulator has issued an industry snapshot of AI developments alongside a broader report on regulatory reform in digital-platform markets, both framed as continued observation rather than intervention.
In the middle are the market studies and sector inquiries — the most crowded part of the spectrum. The United States Federal Trade Commission opened an inquiry into cloud-and-model partnerships in January 2024 and reported a year later without bringing a case; France’s Autorité de la concurrence issued an opinion on competition in generative AI in June 2024 and opened a fresh inquiry into conversational agents in 2026; Japan’s Fair Trade Commission, South Korea’s Fair Trade Commission and the Competition Commission of India have all conducted studies of the AI market; and Turkey’s Competition Authority launched a strategic sector inquiry into AI in April 2026. These authorities are examining the same concentration concerns, but none of these steps has yet produced a remedy.
Further along are the completed reviews that examined a transaction and declined to act. The United Kingdom’s Competition and Markets Authority reviewed Amazon’s investment in Anthropic and cleared it in 2024 on the basis that it was not a merger, and the United States Department of Justice’s search-monopoly case against Google ended in September 2025 with a data-sharing remedy rather than a divestiture, expressly allowing Google to keep its Anthropic stake.
At the heaviest end is active enforcement. France’s Autorité moved to lay anti-competition charges against Nvidia in 2024; China’s market regulator opened an anti-monopoly investigation into Nvidia in December 2024, an action that tracks the United States–China dispute over chips and export controls at least as closely as competition doctrine; and Singapore’s regulator has stated that companies can be held liable for AI-related antitrust harms. The decisive point is that this enforcement end is not a regional cluster: France, a major Western authority, sits beside China here, while the United States and the United Kingdom sit at the clearance end. Region does not predict intensity; a jurisdiction’s general enforcement posture and resources do. For firms structuring AI deals, the practical question is therefore not whether an authority is Western or Asian but where on this spectrum it sits — light-touch monitoring, an open study, a completed clearance with conditions, or a regulator already willing to bring charges.
5) Compute control is enforced at the border, one shipment at a time — even as the formal rules loosen
Compute is the one lever over AI that operates internationally. Within the tracker, chips and data centres appear in only 18 jurisdictions across 78 measures, one of the more concentrated distributions in the dataset.
The United States set the controls. It imposed extensive export controls on advanced chip-making equipment in December 2024 and in January 2025 issued the AI Diffusion Rule, which would have set tiered limits on exports to most of the world. But an export control is only as strong as its weakest transshipment point: a chip that cannot be sold directly to a restricted buyer can still be re-routed through a third country. Diversion is therefore the central vulnerability, and the enforcement that followed concentrated on the transshipment hubs. The United States signalled curbs on GPU sales to Malaysia and Thailand in July 2025, explicitly to stop onward smuggling to China; Singapore charged three men over a fraud case linked to Nvidia chips in February 2025 and opened a probe into whether servers shipped to Malaysia contained restricted Nvidia chips; Malaysia tightened its own controls on US-origin AI chips in July 2025; and the United States Department of Justice charged three individuals in March 2026 with unlawfully diverting US AI technology to China. The controls sit at the top of this chain, the diversion routes run through Southeast Asia, and the arrests and tightened rules are the policing of those routes.
Meanwhile, the controls shifted from blanket denial toward selective access used as leverage. The United States rescinded the AI Diffusion Rule in May 2025 before it took effect and in November 2025 approved the sale of up to 70,000 advanced chips to firms in the United Arab Emirates and Saudi Arabia under bilateral arrangements — access granted in exchange for alignment rather than denied outright. The lever is being repurposed, rather than relaxed. Chokepoints are tightened where diversion happens, loosened where access can be traded for strategic alignment.
The limit of any such lever is that its targets build their way around it. China responded by requiring new state-funded data centres to use domestically produced chips in November 2025, decoupling toward a self-sufficiency that erodes the lever’s future power — and the same instinct is driving sovereign-capability spending well beyond China, from the United Arab Emirates, Malaysia and Rwanda partnership to Indonesia’s AI Talent Factory and Canada’s sovereign-infrastructure agreement with TELUS. Within a few years the origin and licensing of computing power may come to resemble export-control compliance more than ordinary procurement, with supply contracts carrying end-use conditions; the treatment of a model’s national origin as a security factor, discussed below, follows the same logic, and firms building on controlled hardware should anticipate an obligation to document their customers, as regulated exporters already do.