


Solo to Global - how I mapped the world's AI laws
The behind-the-scenes of how I built the Global AI Regulation Tracker that now tracks all 195+ countries, all by myself.


Hi there, I’m Ray - a tech lawyer, developer and creator of the Global AI Regulation Tracker.
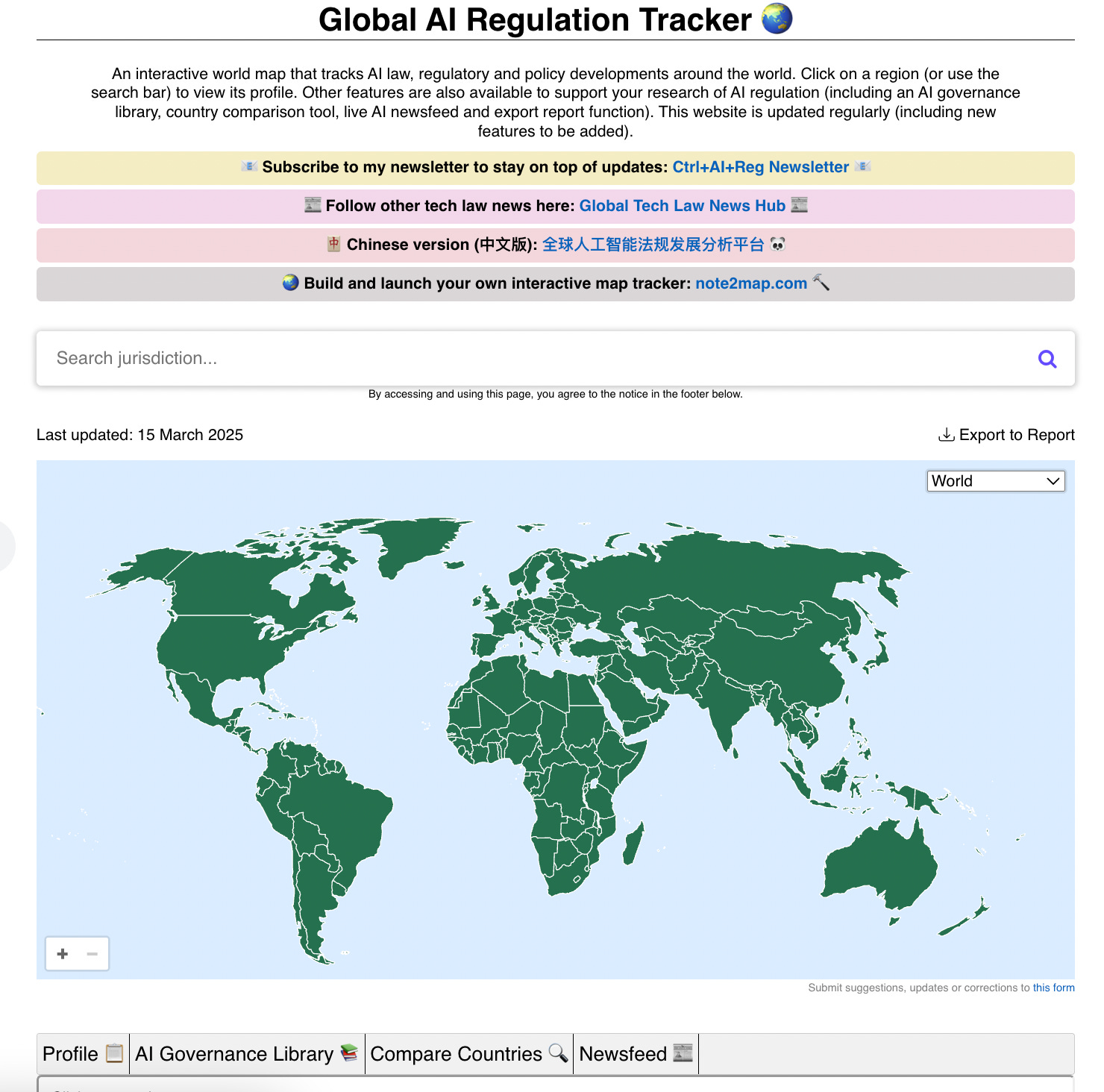
My tracker is an interactive world map that tracks AI law, regulatory and policy developments around the world. Launched in May 2023 and free-to-access, it’s become one of the highly-ranked resources for the AI community around the world, with currently 41,000+ active users (and growing).
In February 2025, I finally completed the entire map, covering all 195+ countries. From the US to Andorra to Kyrgyzstan to Cameroon to Belize…every corner of the globe (including micro-states and islands) now has at least some profile or news update around AI policy or regulation. See my milestone post on Linkedin.
To celebrate this milestone, I’ve written this blog to answer FAQs and shed light on how I built this tracker all by myself from start to finish in my own time and cost (including design, coding, curation, writing and maintenance).
This blog is in a FAQ-style so that you can jump to the section that interests you the most. Hope you enjoy!
CONTENTS
How did AI regulation become my passion?
What inspired me to build the tracker?
How did I design and build the tracker?
How do I update the tracker?
Why semi-automate, but not fully automate?
Why is the tracker available for free?
What other side features have I built?
How do I find time for this project?
Will I open source my dataset?
How long will I continue this tracker?
How did AI regulation become my passion?
Quite a niche passion, right? It’s a long backstory. But in short, AI regulation was a passion that organically grew from my other passions for AI, law, history and geopolitics.
Growing up, I was obsessed with machines and robots, inspired by shows like Thomas the Tank Engine, Brum, Astro Boy, and Iron Man. According to my parents I was already showing a ‘builder’ spirit from as early as the age of three (before I could even speak). I was creating my own toys and gadgets (e.g. a toy train made from toilet paper rolls, matchboxes and bottle caps). I loved building toys more than playing with the toy itself.
That builder spirit continued as I got older. In high school, I picked up coding as a hobby because I wanted to write my own games, and this led to building websites, mobile apps and other random projects throughout uni and work.
I got into machine learning during the COVID-19 lockdown when dance classes (another hobby of mine) shut down which inspired me to experiment with using AI to monitor and evaluate my dance videos. It worked, and my project went viral worldwide when I applied my algorithm to analyse and rank K-pop dances on Youtube. That was the start of my Youtube name ‘techie_ray®’, which has since evolved into my brand for my personal content and apps.
So if I loved building so much…how on earth did I fall into law?
Well, alongside my AI/robots obsession, I also grew up playing chess. I just love the logical strategic gameplay of chess. I guess this influenced what I liked to read, as I found myself liking ‘big-brained’ genres like crime and legal thriller (e.g. Ace Attorney, Detective Conan, John Grisham, The Diamond Brothers) where there was an element of piecing together bits of evidence to uncover the truth. Naturally, this got me interested into either law or forensics as a career.
What tilted me towards law (over forensics) was in high school when I chose to study History, Economics and Legal Studies as my electives. I didn’t expect a ‘builder’ spirit like me would like humanities subjects, but I really enjoyed the exercise of analysing evidence and coming to your own opinion of the world, especially on topics of war, geopolitics and trade, which made me realise I really like ‘big picture’ (i.e. law) stuff rather than fine details (i.e. forensics). That’s how I also got interested in geopolitics, regularly reading essays and listening to podcasts on global affairs.
So I chose to study law for uni, but still kept up my passion for AI/tech hobby by coding on the side. Naturally, “tech law” became my career goal so I chose electives that were close to that area (e.g. Intellectual Property, Commercial Contracts, Privacy). My favourite was Commercial Contracts because that’s where I got to appreciate the art of precise and subtle drafting to shape the way we do commerce and manage risk. How mere words on a paper can affect that way we buy, sell and use technology. It taught me the power of language. Absolutely mindblowing.
And this is where everything came together. Throughout uni, I found myself procrastinating on the internet reading news and blog posts about the ‘trolley problem’, self-driving cars, algorithmic bias and other philosophical essays around AI. But it was the idea of the EU AI Act (first raised in 2019) that got me into the rabbit hole of “AI regulation”. And omg, it was the cross of everything I love - AI, legal drafting and spicy geopolitics.
I began jotting down my thoughts and opinions in a diary. I was especially interested in how different countries drafted their laws to deal with AI, such as what constructs and terminology they would use, the precision of their definitions, the scope of operative provisions, etc. It’s like watching a chess game but through words.
I consistently journalled as a hobby throughout law school and in the initial years of my career. I didn’t initially have any particular goal for this notebook other than to practise my writing and “lets-write-this-down-in-case-it-might-be-useful”. In retrospect, it was a smart move.
What inspired me to build the tracker?
Writing my diary led me to a newfound passion for writing. And why not share my writings?
So I began posting my ‘diary’ thoughts on AI regulation on LinkedIn. This was still pre-ChatGPT days when AI regulation was an ultra niche topic. For the first two years of my LinkedIn journey (2020-21), my posts got modest attention, but I didn’t mind because I enjoyed writing.
But then came ChatGPT in November 2022. This caused a massive surge of interest in AI. The LinkedIn algorithm gods then blessed me, bumping up my AI regulation posts to a broad audience. As my audience grew, I thought it’d be useful to centralise my writings in one website, organised and searchable by country.
That's how the AI Global Regulation Tracker was born. After one whole weekend of hacking, I launched the tracker on 23 May 2023. When I announced the launch on Linkedin, I was overwhelmed with positive feedback, which validated to me that this was actually useful and needed by the community (see also “Why is my tracker available for free?” below).

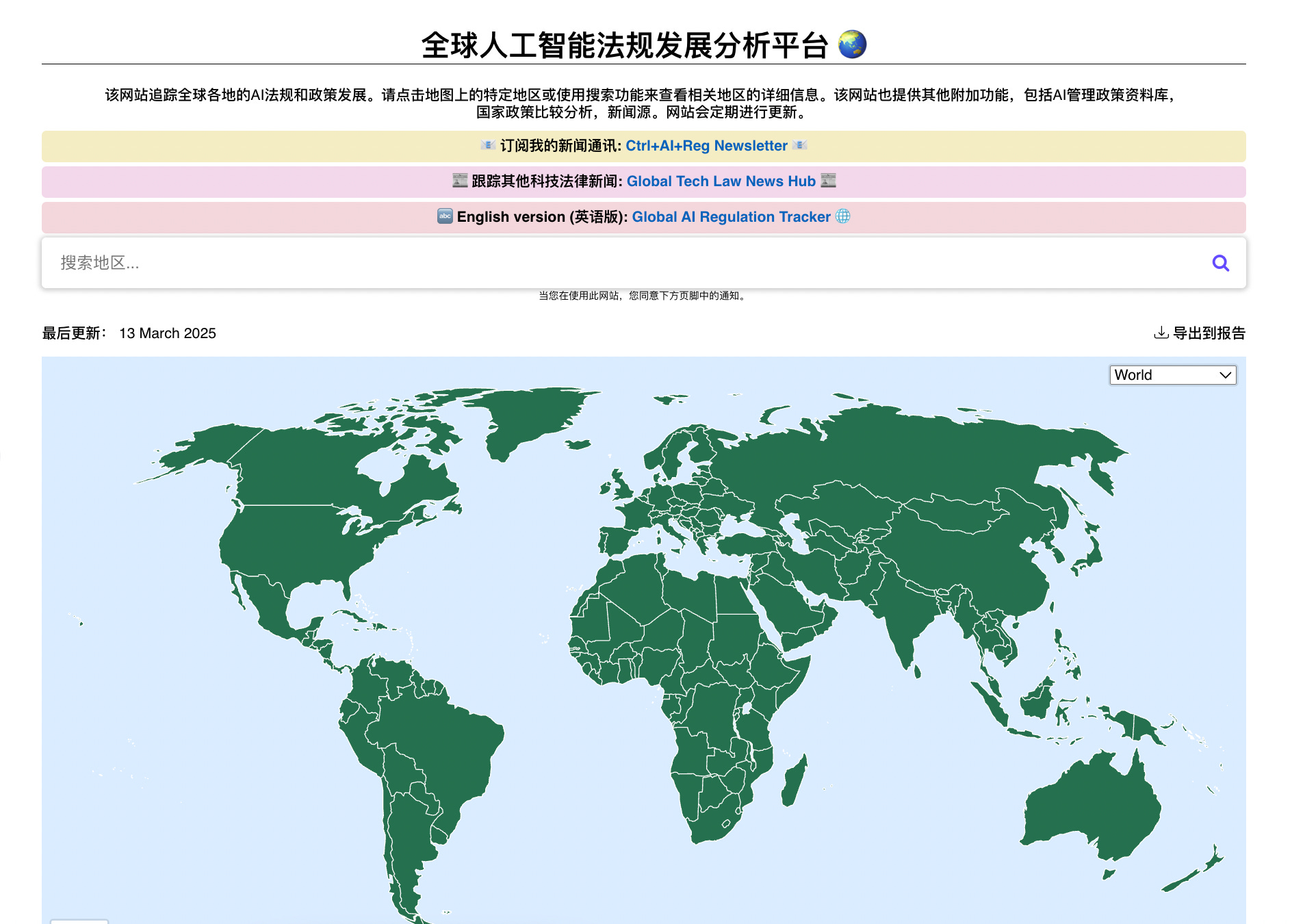
How did I design and build the tracker?
It helped that I already had my own personal website (www.techieray.com), so building the tracker was just a matter of adding a new page to my site.
While there were other AI regulation trackers available, I found all of them to be either not user-friendly (i.e. too many clicks or too laggy), hard to read (i.e. too much legal language), severely out-to-date, and/or behind a paywall.
So for my tracker, I wanted a simple and intuitive layout - i.e. a massive interactive world map where you can click on a country to display a one-page profile of its AI regulations (including latest news updates, my personal commentary and Linkedin posts).
Part of the simplicity was my “one-click-rule” - i.e. anything should be accessed in one click. No login. No fancy menus. No side pages.
For the styling, I was inspired by the ‘clean vanilla’ look of Wikipedia and Notion. I also shopped around for open-source world map templates, eventually settling with this template (under a MIT licence) because I liked its sleek minimalist map design.
I wrote the content manually. I initially focused on collating profiles for the major jurisdictions - i.e. EU, USA, China, UK, Canada, Japan, India, Singapore, and Australia. Fortunately I was already familiar with these jurisdictions so the research process was relatively quick. But drafting the profiles took some time because I had to write them in JSON format directly in the source code of the tracker (see sample below). It’s a cumbersome design which would pose challenges later down the track (see “How do I update the tracker?”).
{
"desc": " Outlines 8 ethics principles - (1) human, societal and environmental wellbeing, (2) human-centred values, (3) fairness, (4) privacy protection and security, (5) reliability and safety, (6) transparency and explainability, (7) contestability, and (8) accountability.",
"href": "https://www.industry.gov.au/publications/australias-artificial-intelligence-ethics-framework/australias-ai-ethics-principles",
"label": "Commonwealth AI ethics principles (2019):"
},How do I update my tracker?
Setting up the tracker is one thing. Populating and updating the tracker is a whole other challenge 🙈.
After all, a tracker is only useful when it’s up-to-date.
It was all very manual at the start.
Manually monitor for updates from a wide range of new sources, government websites, press releases, etc. I would start with searching “AI regulation” on Google News, Bing News, Perplexity and Linkedin for the secondary news updates, then do targeted searches for the relevant primary sources.
Review the source, and manually summarise it in my own words. I actually enjoy the writing process. But sometimes I do feel lazy and use Perplexity to produce a draft summary (which I then verify and tweak). I found that Perplexity tends to produce more accurate summaries than Bing Copilot, Gemini and ChatGPT.
Add my summary into the source code of my website, and re-upload my updated website to my server. I had to do it this way because I had initially set up my website as a basic static webpage (i.e. content is hardcoded in the website’s source code), rather than a dynamic web app linked to a cloud database.
On average, this routine would take me an hour of solid manual effort, but became less sustainable as I kept adding new regions to the tracker (which expanded the scope of research). I also did this routine every late night before bed which cut into my sleep time. I had to optimise my workflow.
So my first optimisation step was to automate the news curation. I hacked together a Python bot that would call various news APIs (e.g. News API, Bing News API) and web scrapers (e.g. Google News scraper) to retrieve the latest AI regulation news of the day for each profiled country in my tracker. It took me a lot of trial-and-error to optimise the search parameters and configurations for each API/scraper so that they would prioritise authoritative primary sources (e.g. official government press releases) over secondary sources (e.g. third party news articles, blogs, etc). Now my bot is able to get me 3-5 high-quality updates upon my command, cutting my workflow time by half (at step 1).
I’m unable to share my bot publicly due to certain API restrictions, however, I have adapted and repurposed my bot into a public news aggregation platform (my other project) called the Global Tech Law News Hub.
My second optimisation targeted step 3, which required a re-design of my website’s architecture. I turned my static website into a dynamic web app, and migrated my content into the cloud (Google Firebase). I learnt how to deploy cloud functions, database and web app frameworks (e.g. Flask). I also created a database entry app where I could draft and push my updates to my tracker via my phone anytime anywhere. This saved me a further ~10 minutes of manual effort.
My third optimisation step was to combine the news curation, summarisation and database entry steps into one automated workflow. I initially experimented with workflow platforms like Zapier but found it too clunky (and expensive) for my needs. I also updated my news bot to directly curate, summarise and post updates to my tracker which was incredibly fast (and probably even something that I could sell on its own!) but I didn’t feel comfortable with updates being posted to my tracker without my review.
So I eventually developed a ‘semi-automated’ workflow where I merged my news bot and database entry app into one consolidated app (private to me only) that would curate updates for me and produce AI-generated summaries which I would use as a reference to draft my own manual summary, and then post to the tracker. This is my current workflow, which now on average takes ~10 minutes for me.
Over time I’ve added minor improvements to save more time, such as retrieving corroborating news sources (to help with my manual verification/review) and automatic language translations (for foreign language news sources).
Why semi-automate, but not fully automate?
It might be surprising that I scaled back from full automation to semi automation. Why?
As mentioned, I felt more comfortable (and more responsible) to manually review updates before posting to the tracker.
There’s also a copyright benefit to manually drafting content (rather than relying on raw AI-generated content).
But the bigger reason is that my brain retains content far better when I manually summarise by hand. I don’t think it's photographic memory (I'm not a Mike Ross or Magnus Carlsen), but my brain does tend to memorise everything that I type/write on my tracker. I lose this memory advantage when things are completely automated (where I'm only reading).
And that has been my biggest gain from this project. The tracker has primarily been a notebook (or 'cheat-sheet') for me.
The real tracker is in my brain. There are some deep patterns across the data which I can only mentally see in my head, and would love to build out new features to visualise this to you.
So I like to keep things semi-automated for now. It's slower but meaningful to me.
Why is my tracker available for free?
As mentioned, the tracker is my central hub for my thoughts and notes on AI regulation. This has always been its primary purpose, such that even if no one uses my tracker, it’s still useful for me.
Beyond that, as the user base grew, I found the tracker to be my unique way of giving back to the world. By keeping it free to access, I hope my tracker can provide a gateway for individual developers, entrepreneurs, teachers, researchers and students around the world to access the AI regulations that surrounds and affects them. It’s been super motivating whenever I hear stories that my tracker has helped users with legal research, exploring markets for product launch, writing research essays, drafting policy papers, delivering lectures, etc on the topic. This alone gives me a lot of meaning to my life, making my efforts and costs worthwhile.
What about the costs? So far, the costs have been manageable (mostly just server and API costs), and recoverable through minor ad revenue generated by my website.
I’ve also been building premium side features to support the free content, such as:
✔️ export the tracker’s data into a report (available now)
✔️ interactive map template (available now - www.note2map.com)
💡 API access to the tracker’s data (under development)
💡 data visualisation and infographics (under development)
But whether monetised or not, I’ve gained a lot from my tracker in other ways such as:
💬 Connecting with people around the world through my tracker
🌏 Learning flags, geography, culture and history (i.e. “digitally travelling”)
🌐 Seeing geopolitical and regulatory patterns
I see the tracker as sort of my unique path of becoming more informed and active ‘global citizen’.
What other features have I built?
In parallel to keep things up-to-date, I’m also constantly building new features, which is fun because each feature is like it’s own side project.
Here’s the story behind each side feature, listed below in chronological order.
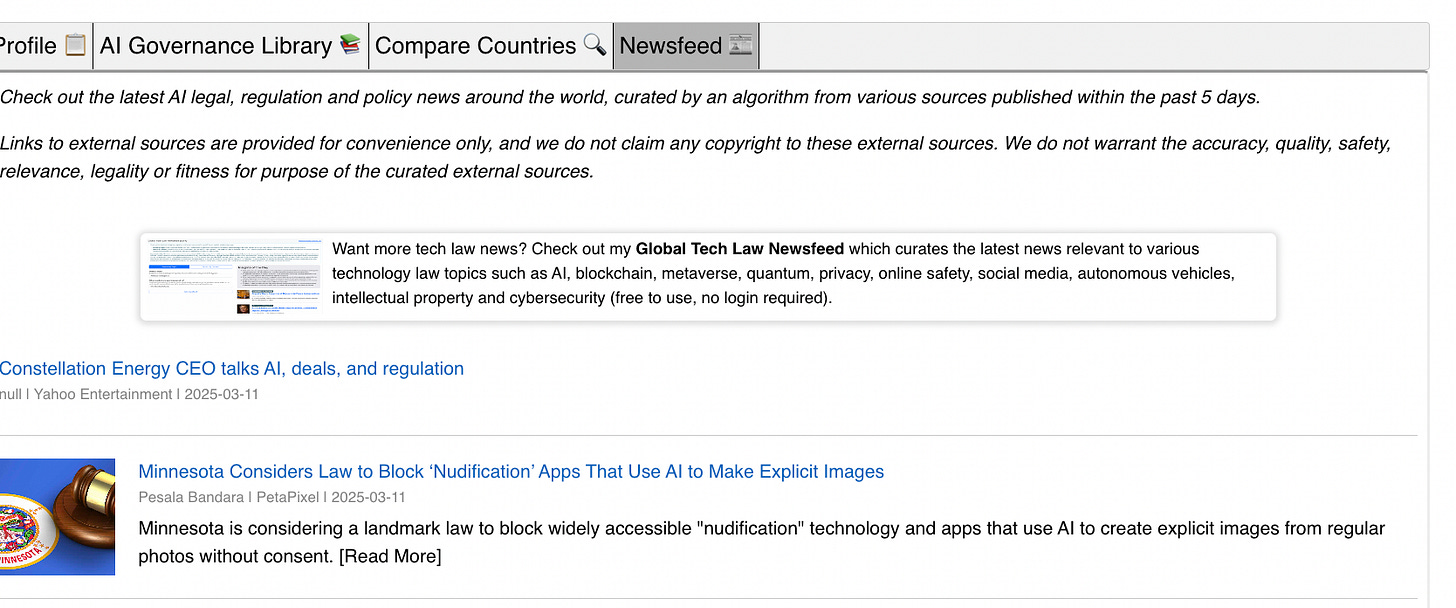
Live Newsfeed. When I was still curating news manually, I thought it’d be useful to add a live raw newsfeed as a ‘back up’ in case the tracker content was out of date and the user wanted to see the latest news. I built this feature using the Bing News API (paid plan), configured to search for AI regulation news over the past 5 days. This feature is now available in the “Newsfeed” tab of the tracker.
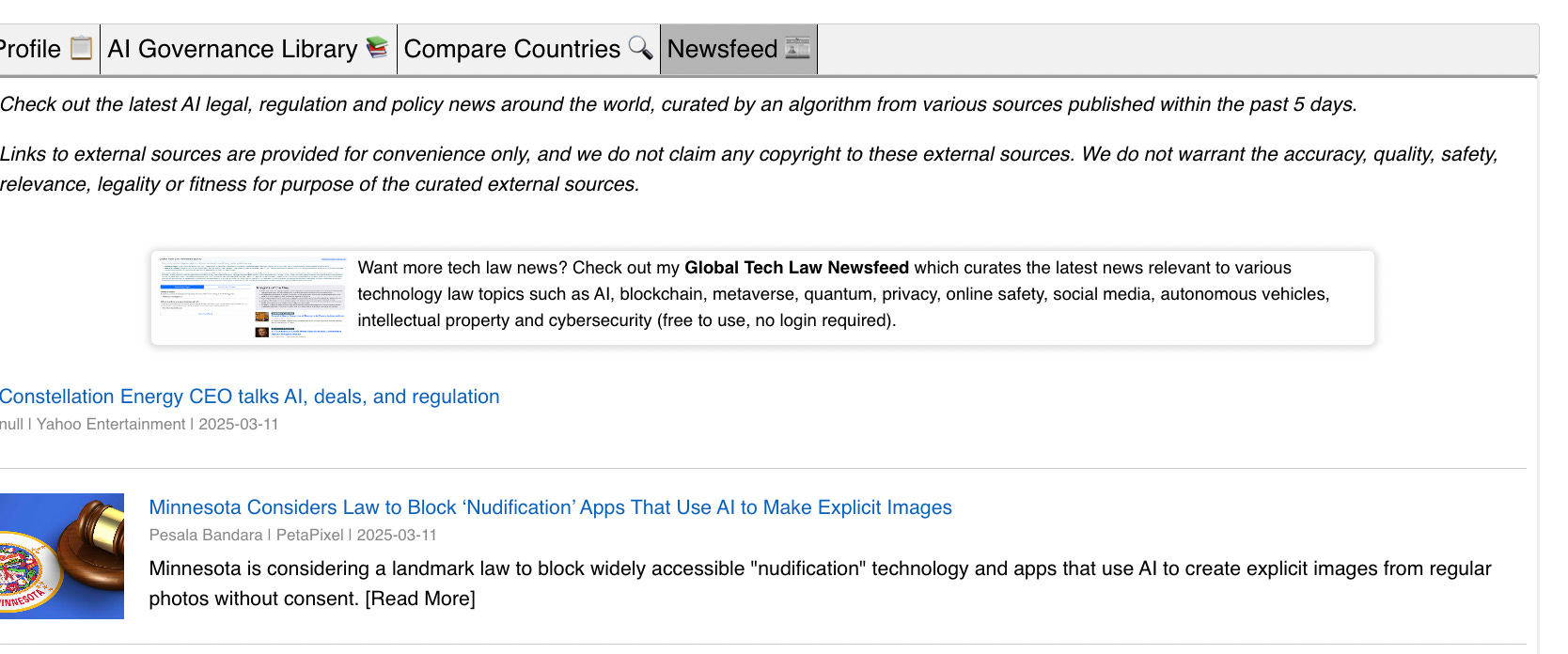
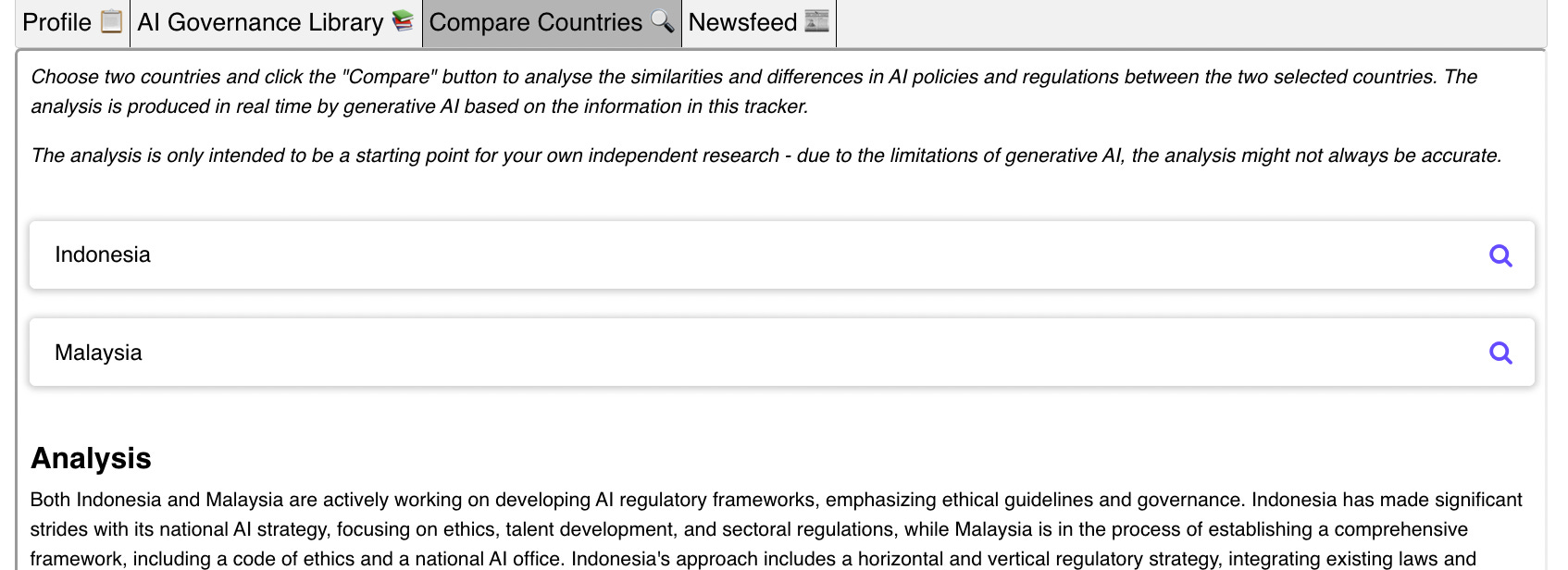
Compare jurisdictions analysis. I had this idea very early on when I was building the tracker. Personally, I’m always interested in comparing the regulatory approaches between countries. So as the content on my tracker grew, it was only natural for me to build a function that allowed you to compare any two given countries. The comparative analysis is auto-generated by generative AI (i.e. GPT-4) based on the content on my tracker (i.e. a RAG system). This feature is now available under the “Compare Countries” tab of the tracker.
AI governance library. Sometimes I would come across useful AI governance resources online that weren’t exactly legislative/regulatory updates for me to post to the tracker, yet were too useful to ignore. So that’s how I came up with an idea of a separate repository for public frameworks, policies, templates and other useful practical resources on AI governance and risk management (which I would manually curate). Here I got to learn how to build search algorithms and catalogue interfaces. I also added a “Recommended For You” function where GPT-4 would cherry pick resources from the list most suitable to your description. This feature is available under the “AI Governance Library” tab of the tracker. See also my Linkedin launch post.
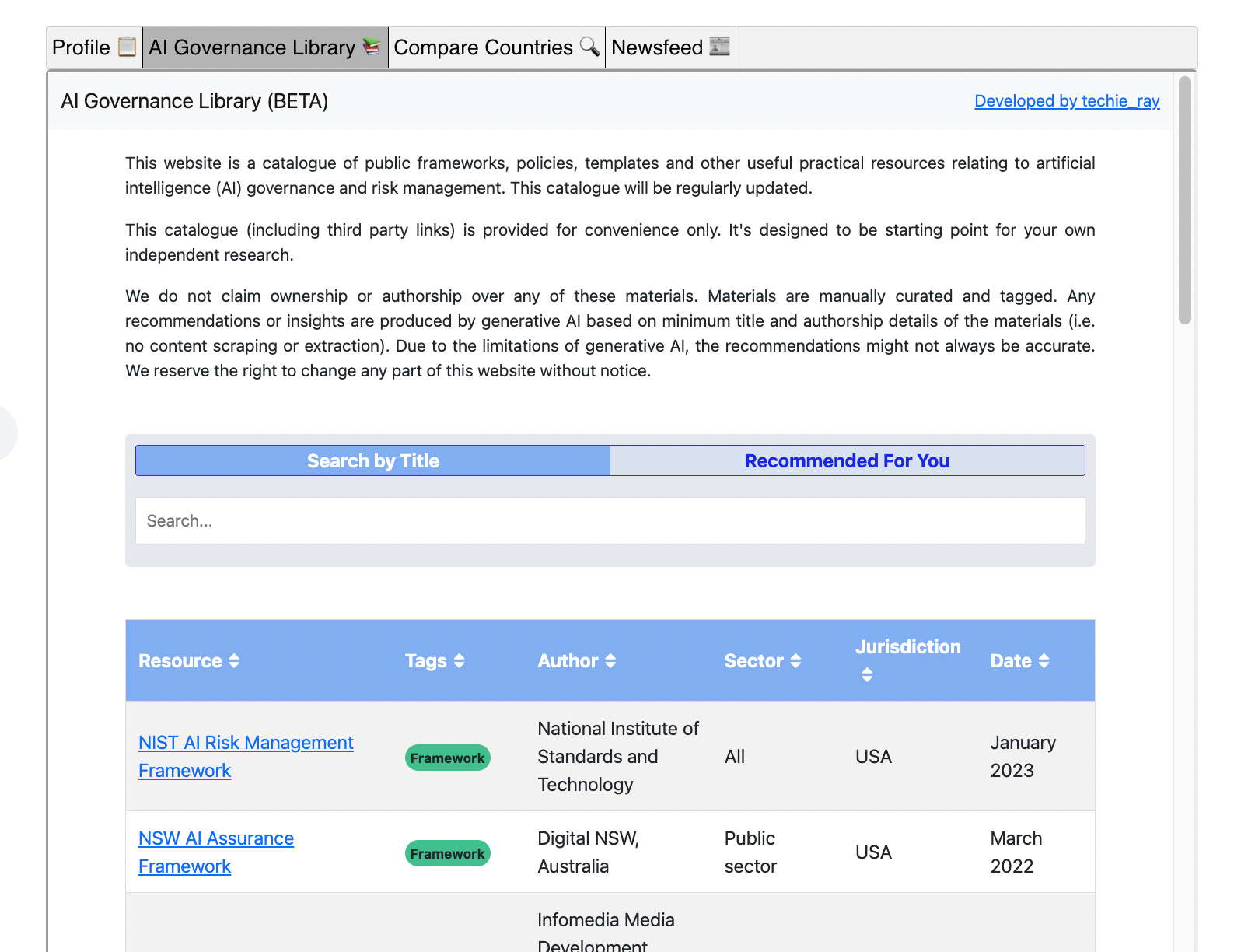
Chatbot. This was more of an experiment but I briefly added a GPT-4 powered chatbot to the tracker that would respond to queries on AI regulation based on the tracker’s content. It was opportunity for me to learn the embedchain framework and the mechanics of a chatbot. However, in January 2025, I discontinued the chatbot feature because it wasn’t a widely used feature (+ expensive API costs), nor did it produce reliable responses.
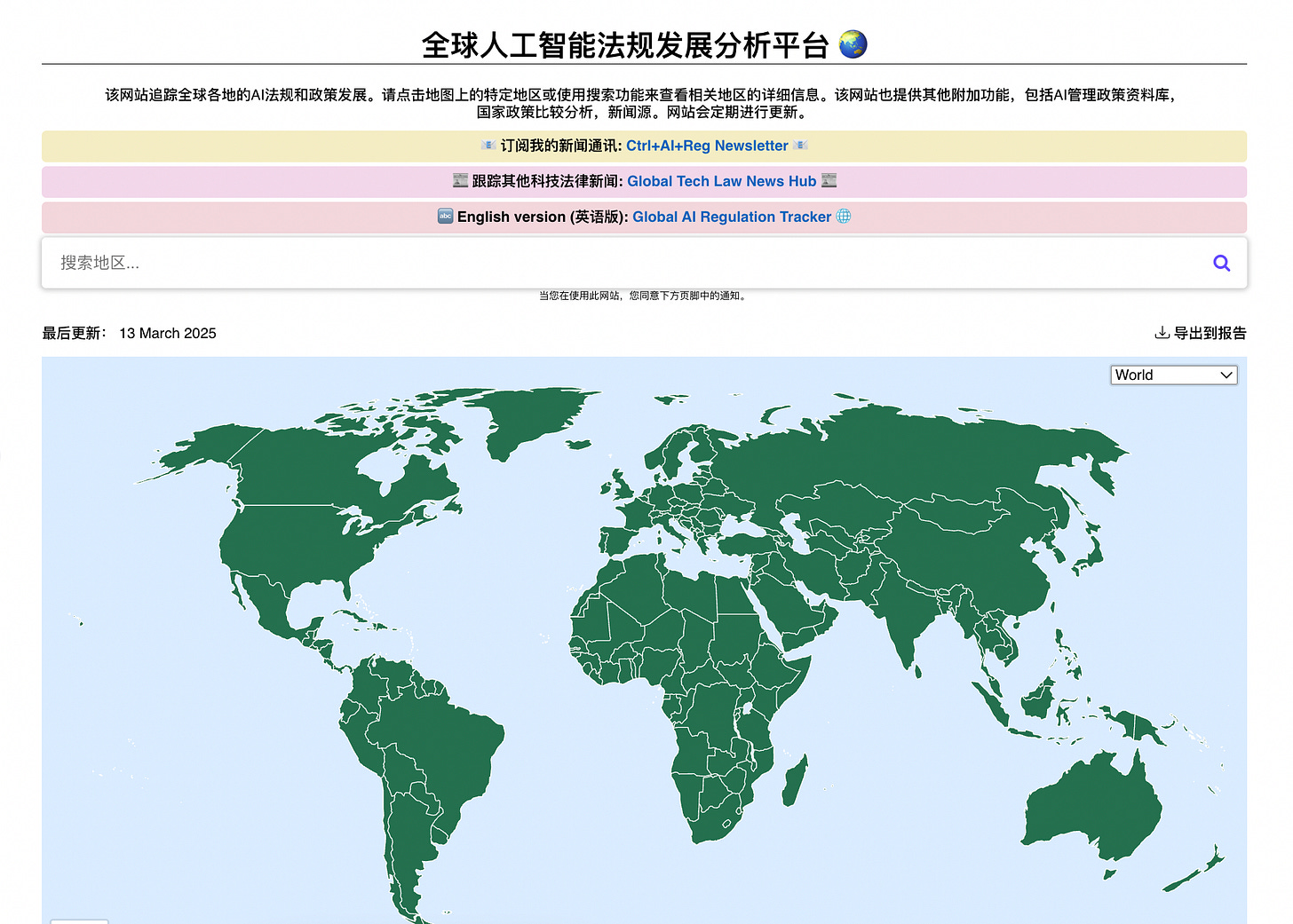
Chatbot function (discontinued since January 2025) Chinese version. This is not exactly a feature, but a separate website. I launched a Chinese version of my tracker to accomodate for my growing Chinese-speaking audience (i.e. Mainland China, Hong Kong, Taiwan, Singapore). I also took this as an opportunity to practise my Chinese writing skills. To date, I have been updating both English and Chinese trackers at the same time.
Note2Map. This is a whole separate project but I basically built a ‘template’ of my tracker for anyone who wants to build their own interactive map tracker. See my launch post below and video demo.

How do I find time for this project?
This is a personal project that I do outside of my full time job as a lawyer.
On weekdays, I would spend every night before bed (~12am-1am) to read and post updates (which ensures my tracker is up-to-date daily). Thanks to my optimisation efforts, this process has been less and less time consuming.
The weekends is where I go hard, making the most of my spare time to build new features or add new country profiles. I’ve been doing this consistently for the past 2 years, with a goal of adding a new country every week. Progress is small and slow, but it eventually adds up into something big.
So basically, consistency. But the other key thing is that…I don’t see this project as work, but a hobby. Curating and writing content is my way of relaxing after a long day of work.
This enjoyment, plus the meaning behind it all, is what drives my consistency.
Will I open source my dataset?
Possibly, but only when I’m comfortable that my dataset is clean, complete and reliable for release into open source. Perhaps I’ll release one piece at a time. In the meantime, the content on the tracker is already free to access anyways, and users are welcome to contribute updates via this form.
How long will I continue this project?
For as long as possible. Even if I eventually move on, I’ll be sure to make arrangements to ensure this project continues for the greater good.
Thank you for your work and you are in my tracker: https://github.com/robomotic/awesome-guide-ai-safety
Congrats Ray, keep up the good work! I love your tracker, and it‘s great to see that you can combine your passions with that project!